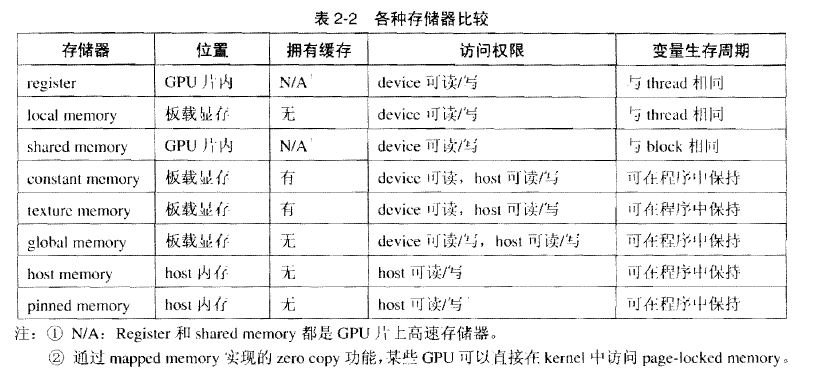
CUDA存储器类型:
每个线程拥有自己的register and loacal memory;
每个线程块拥有一块shared memory;
所有线程都可以访问global memory;
还有,可以被所有线程访问的只读存储器:constant memory and texture memory
1、 寄存器Register
寄存器是GPU上的高速缓存器,其基本单元是寄存器文件,每个寄存器文件大小为32bit.
Kernel中的局部(简单类型)变量第一选择是被分配到Register中。
特点:每个线程私有,速度快。
2、 局部存储器 local memory
当register耗尽时,数据将被存储到local memory。如果每个线程中使用了过多的寄存器,或声明了大型结构体或数组,或编译器无法确定数组大小,线程的私有数据就会被分配到local memory中。
特点:每个线程私有;没有缓存,慢。
注:在声明局部变量时,尽量使变量可以分配到register。如:
unsigned int mt[3];
改为: unsigned int mt0, mt1, mt2;
3、 共享存储器 shared memory
可以被同一block中的所有线程读写
特点:block中的线程共有;访问共享存储器几乎与register一样快.
1 //u(i)= u(i)^2 + u(i-1) 2 //Static 3 __global__ example(float* u) { 4 int i=threadIdx.x; 5 __shared__ int tmp[4]; 6 tmp[i]=u[i]; 7 u[i]=tmp[i]*tmp[i]+tmp[3-i]; 8 } 9 10 int main() {11 float hostU[4] = {1, 2, 3, 4};12 float* devU;13 size_t size = sizeof(float)*4;14 cudaMalloc(&devU, size);15 cudaMemcpy(devU, hostU, size,16 cudaMemcpyHostToDevice);17 example<<<1,4>>>(devU, devV);18 cudaMemcpy(hostU, devU, size,19 cudaMemcpyDeviceToHost);20 cudaFree(devU);21 return 0;22 }23 24 //Dynamic25 extern __shared__ int tmp[];26 27 __global__ example(float* u) {28 int i=threadIdx.x;29 tmp[i]=u[i];30 u[i]=tmp[i]*tmp[i]+tmp[3-i];31 }32 33 int main() {34 float hostU[4] = {1, 2, 3, 4};35 float* devU;36 size_t size = sizeof(float)*4;37 cudaMalloc(&devU, size);38 cudaMemcpy(devU, hostU, size, cudaMemcpyHostToDevice);39 example<<<1,4,size>>>(devU, devV);40 cudaMemcpy(hostU, devU, size, cudaMemcpyDeviceToHost);41 cudaFree(devU);42 return 0;43 }
4、 全局存储器 global memory
特点:所有线程都可以访问;没有缓存
//Dynamic__global__ add4f(float* u, float* v) {int i=threadIdx.x; u[i]+=v[i];}int main() { float hostU[4] = {1, 2, 3, 4}; float hostV[4] = {1, 2, 3, 4}; float* devU, devV; size_t size = sizeof(float)*4; cudaMalloc(&devU, size); cudaMalloc(&devV, size); cudaMemcpy(devU, hostU, size, cudaMemcpyHostToDevice); cudaMemcpy(devV, hostV, size, cudaMemcpyHostToDevice); add4f<<<1,4>>>(devU, devV); cudaMemcpy(hostU, devU, size, cudaMemcpyDeviceToHost); cudaFree(devV); cudaFree(devU); return 0;}//static__device__ float devU[4];__device__ float devV[4];__global__ addUV() {int i=threadIdx.x; devU[i]+=devV[i];}int main() { float hostU[4] = {1, 2, 3, 4}; float hostV[4] = {1, 2, 3, 4}; size_t size = sizeof(float)*4; cudaMemcpyToSymbol(devU, hostU, size, 0, cudaMemcpyHostToDevice); cudaMemcpyToSymbol(devV, hostV, size, 0, cudaMemcpyHostToDevice); addUV<<<1,4>>>(); cudaMemcpyFromSymbol(hostU, devU, size, 0, cudaMemcpyDeviceToHost); return 0;} 5、 常数存储器constant memory
用于存储访问频繁的只读参数
特点:只读;有缓存;空间小(64KB)
注:定义常数存储器时,需要将其定义在所有函数之外,作用于整个文件
1 __constant__ int devVar;2 cudaMemcpyToSymbol(devVar, hostVar, sizeof(int), 0, cudaMemcpyHostToDevice)3 cudaMemcpyFromSymbol(hostVar, devVar, sizeof(int), 0, cudaMemcpyDeviceToHost)
6、 纹理存储器 texture memory
是一种只读存储器,其中的数据以一维、二维或者三维数组的形式存储在显存中。在通用计算中,其适合实现图像处理和查找,对大量数据的随机访问和非对齐访问也有良好的加速效果。
特点:具有纹理缓存,只读。
TNE END